Hybrid Tree Search
In this cookbook, we provided a simple example of how to conduct tree search with LLMs. However, this approach comes with the following limitations:
- Retrieval Speed: LLM-based tree search can be slower due to the need for LLM reasoning.
- Summary-based Node Selection: Relying solely on summaries may result in the loss of important details present in the original content.
To address these limitations, we introduce another tree search algorithm for retrieval, which is inspired by AlphaGo.
Value-based Tree Search
For each node in a tree, we can use an AI model to predict a value that represents how likely this node is to contain relevant information for a given query. A simple value function can be constructed with the following procedure using a pre-trained embedding model:
- Chunking: Each node is divided into several smaller chunks.
- Vector Search: The query is used to search for the top-K most relevant chunks.
- Node Scoring: For each retrieved chunk, we identify its parent node. The relevance score for a node is calculated by aggregating the similarity scores of its associated chunks.
Let N be the number of content chunks associated with a node, and let ChunkScore(n) be the relevance score of chunk n. The Node Score is computed as:

- The sum aggregates relevance from all related chunks.
- The +1 inside the square root ensures the formula handles nodes with zero chunks.
- Dividing by N (the mean) would normalize the score, but would ignore the number of relevant chunks, treating nodes with many and few relevant chunks equally.
- Using the square root in the denominator allows the score to increase with the number of relevant chunks, but with diminishing returns. This rewards nodes with more relevant chunks, while preventing large nodes from dominating due to quantity alone.
- This scoring favors nodes with fewer, highly relevant chunks over those with many weakly relevant ones.
📝 Note: Unlike classic vector-based RAG, in this framework, we retrieve nodes based on their associated chunks, but do not return the chunks themselves.
If the value prediction is accurate, this approach can improve the speed of the LLM-based tree search method. However, if we use a pre-trained embedding model to initialize the value function, it may still miss relevant nodes or struggle to integrate expert knowledge.
Hybrid Tree Search with LLM and Value Prediction
To overcome the limitations of both approaches, we can use the following procedure to combine and leverage the strengths of both methods:
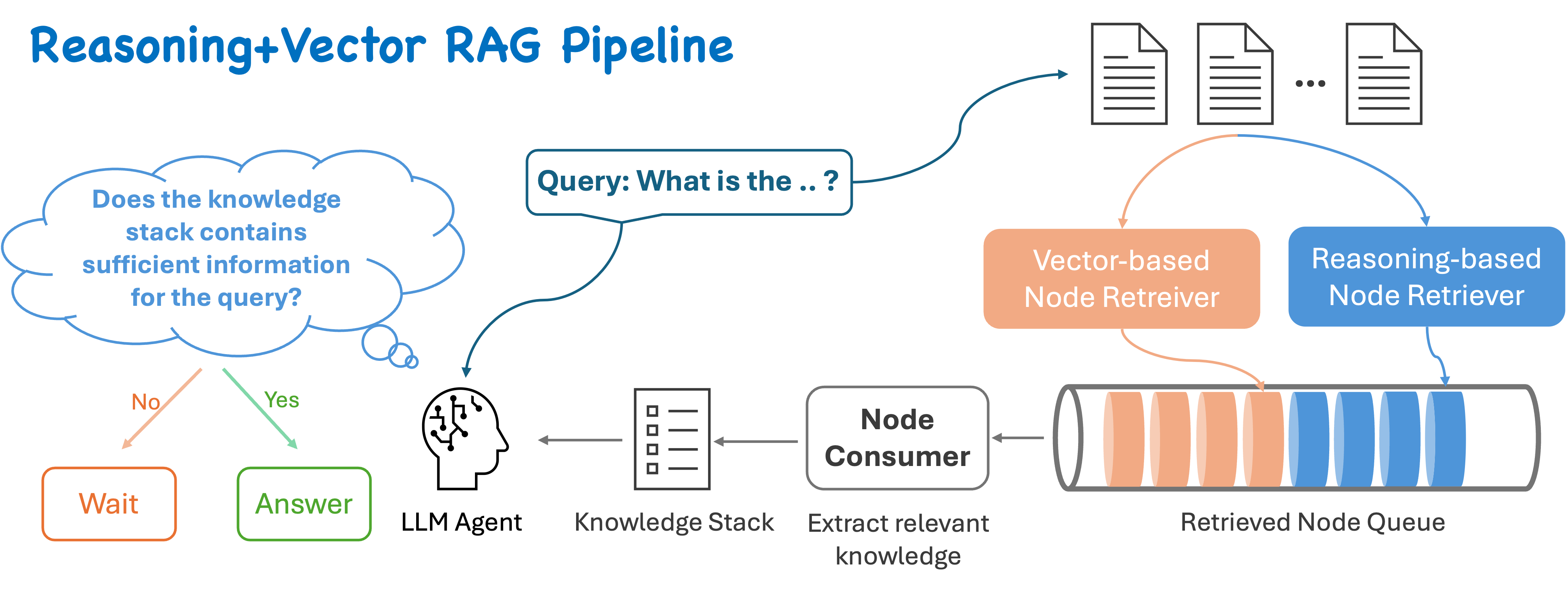
- Parallel Retrieval: Perform value-based tree search and LLM-based tree search simultaneously.
- Queue System: Maintain a queue of unique node elements. As nodes are returned from either search, add them to the queue only if they are not already present.
- Node Consumer: A consumer processes nodes from the queue, extracting or summarizing relevant information from each node.
- LLM Agent: The agent continually evaluates whether enough information has been gathered. If so, the process can terminate early.
This hybrid approach offers the following advantages:
- Combines the speed of value-based methods with the depth of LLM-based methods.
- Achieves higher recall than either approach alone by leveraging their complementary strengths.
- Delivers relevant results quickly, without sacrificing accuracy or completeness.
- Scales efficiently for large document collections and complex queries.
This hybrid approach is the default search method used in our Dashboard and API. Experience the power of PageIndex today!
💬 Help & Community
Contact us if you need any advice on conducting document searches for your use case.